一、hive的安装
注意:安装hive的前提要安装好MySQL和Hadoop
安装hive首先需要启动Hadoop
1、解压hive的安装包
tar -zxvf apache-hive-1.2.1-bin.tar.gz
修改下目录名称
mv apache-hive-1.2.1-bin hive-1.2.1
2、备份配置文件
cd /usr/local/soft/hive-1.2.1/conf
cp hive-env.sh.template hive-env.sh
cp hive-default.xml.template hive-site.xml
3、修改配置文件
vim hive.env.sh
新加三行配置(路径不同就更具实际情况来):
HADOOP_HOME=/usr/local/soft/hadoop-2.7.6
JAVA_HOME=/usr/local/soft/jdk1.8.0_171
HIVE_HOME=/usr/local/soft/hive-1.2.1
4、修改配置文件
vim hive-site.xml
修改对应的配置参数(注意:是修改不是添加)
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://master:3306/hive?characterEncoding=UTF-8&createDatabaseIfNotExist=true&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>/usr/local/soft/hive-1.2.1/tmp</value>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/usr/local/soft/hive-1.2.1/tmp</value>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/usr/local/soft/hive-1.2.1/tmp</value>
</property>
5、复制mysql连接工具包到hive/lib
cd /usr/local/soft/hive-1.2.1
cp /usr/local/moudle/mysql-connector-java-5.1.49.jar /usr/local/soft/hive-1.2.1/lib/
6、删除hadoop中自带的jline-2.12.jar位置在/usr/local/soft/hadoop-2.7.6/share/hadoop/yarn/lib/jline-2.12.jar
rm -rf /usr/local/soft/hadoop-2.7.6/share/hadoop/yarn/lib/jline-2.12.jar
7、把hive自带的jline-2.12.jar复制到hadoop中 hive中所在位置 /usr/local/soft/hive-1.2.1/lib/jline-2.12.jar
cp /usr/local/soft/hive-1.2.1/lib/jline-2.12.jar /usr/local/soft/hadoop-2.7.6/share/hadoop/yarn/lib/
8、启动
hive
Hive架构原理(图)
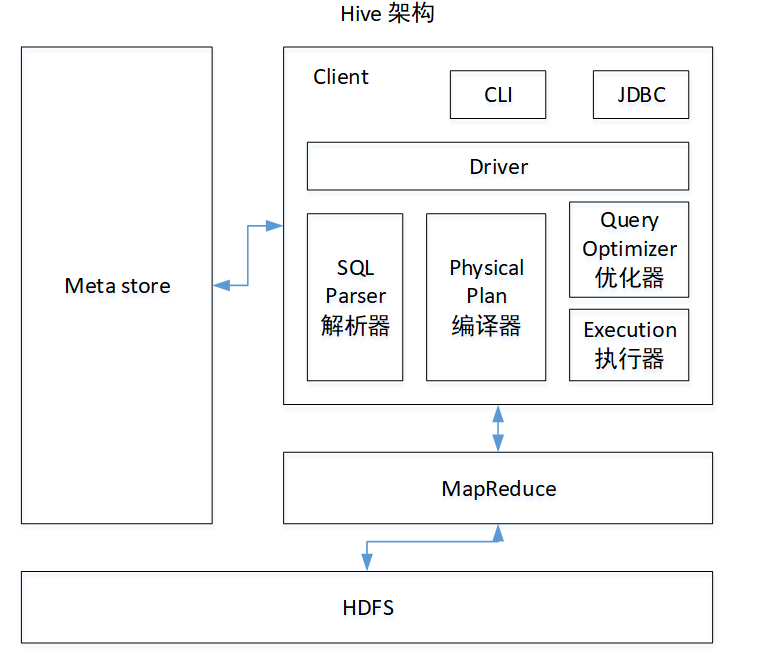
1)用户接口:Client
CLI(command-line interface)、JDBC/ODBC(jdbc访问hive)、WEBUI(浏览器访问hive)
2)元数据:Metastore
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;
默认存储在自带的derby数据库中,推荐使用MySQL存储Metastore
3)Hadoop
使用HDFS进行存储,使用MapReduce进行计算。
4)驱动器:Driver
(1)解析器(SQL Parser):将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
(2)编译器(Physical Plan):将AST编译生成逻辑执行计划。
(3)优化器(Query Optimizer):对逻辑执行计划进行优化。
(4)执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是MR/Spark。
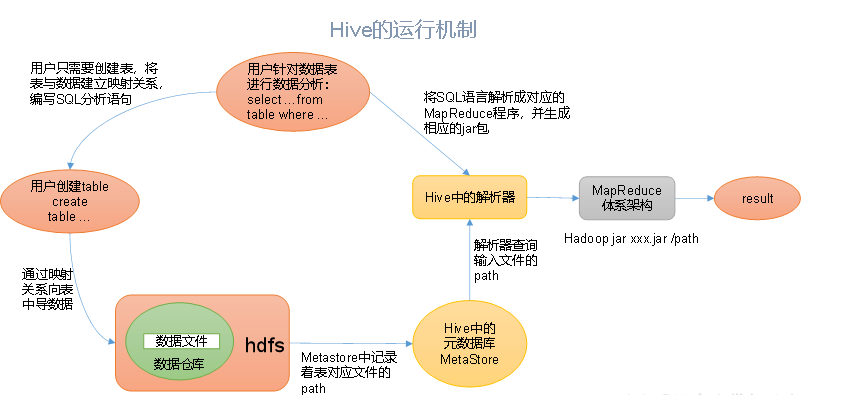
Hive运行机制(图)
Hive通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的Driver,结合元数据(MetaStore),将这些指令翻译成MapReduce,提交到Hadoop中执行,最后,将执行返回的结果输出到用户交互接口。

