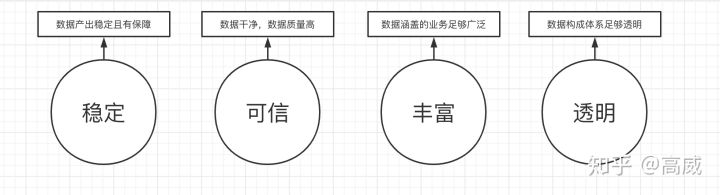
用户画像标签体系
用户画像的核心在于给用户“打标签”,每一个标签通常是人为规定的特征标识,用高度精炼的特征描述一类人,例如年龄、性别、兴趣偏好等,不同的标签通过结构化的数据体系整合,就可与组合出不同的用户画像。
梳理标签体系是实现用户画像过程中最基础、也是最核心的工作,后续的建模、数据仓库搭建都会依赖于标签体系。
为什么需要梳理标签体系,因为不同的企业做用户画像有不同的战略目的,广告公司做用户画像是为精准广告服务,电商做用户画像是为用户购买更多商品,内容平台做用户画像是推荐用户更感兴趣的内容提升流量再变现,金融行业做用户画像是为了寻找到目标客户的同时做好风险的控制。
所以第一步,我们要结合所在的行业,业务去分析我们用户画像的目的。这其实就是战略,我们要通过战略去指引我们最终的方向。

对于电商企业来说,可能最重要的两个问题就是:
现有用户- 我的现存用户是谁?为什么买我的产品?他们有什么偏好?哪些用户价值最高?
潜在客户- 我的潜在用户在哪儿?他们喜欢什么?哪些渠道能找到他们?获客成本是多少?
而对于金融企业,还要加上一条:
用户风险—用户的收入能力怎么样?他们是否有过贷款或者信用卡的逾期?他们的征信有问题吗?
我们做用户画像的目的也就是根据我们指定的战略方向最终去解决这些问题。
在梳理标签的过程还要紧密的结合我们的数据,不能脱离了数据去空想,当然如果是我们必须要的数据,我们可能需要想办法去获取这些数据,这就是数据采集的问题,我们之后会深入的讨论。
先展示两种常见的标签体系,随后我们将按步骤建立我们的标签体系。
电商类标签体系
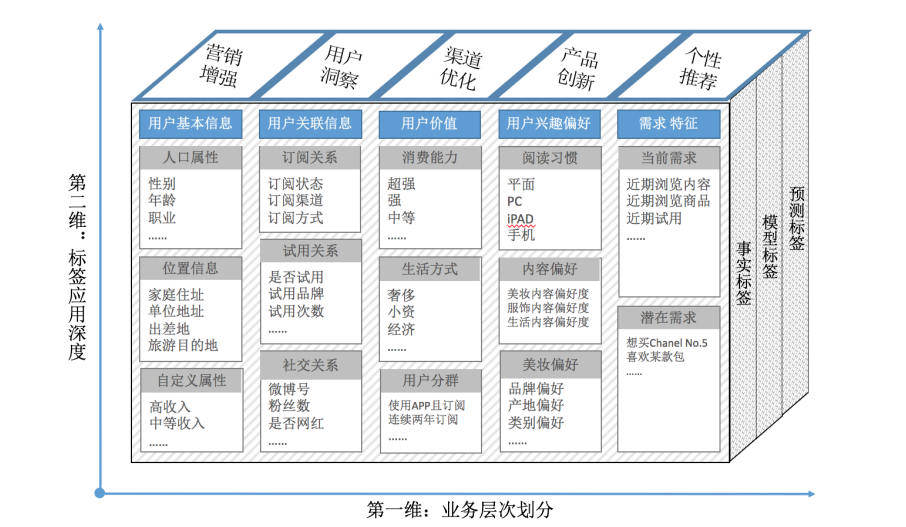
可以看到电商类的标签体系,更关注用户的属性,行为等等信息。那么我们需要的数据也就来源于用户可提供的基本信息,以及用户的行为信息,这些我们可以通过埋点获取,而用户的订单情况也是非常的重要的标签。
金融类标签体系
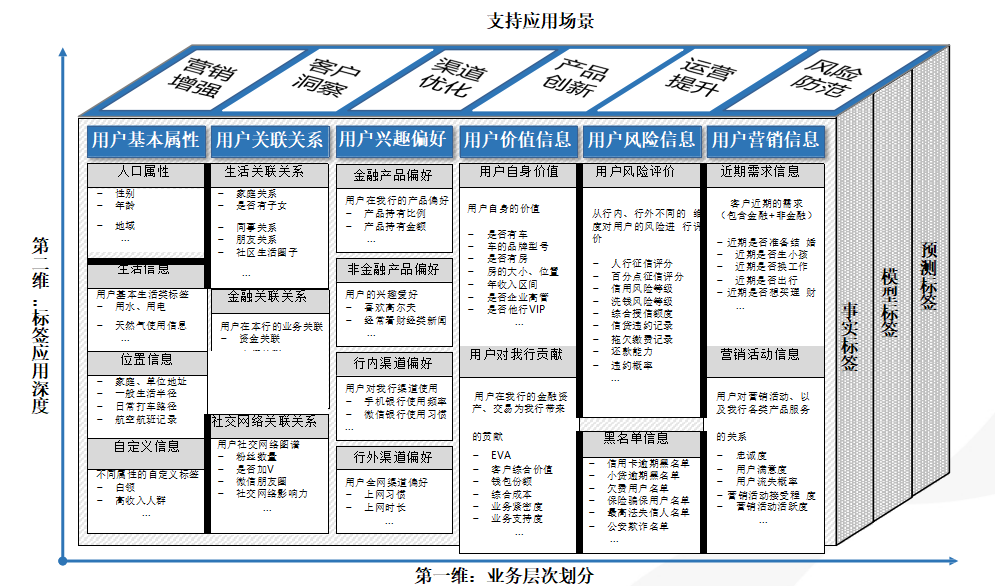
对于金融行业,最明显的区别是增加了用户的价值和用户风险的信息。这些信息在用户申请贷款时一般都可以提供,还有很多信息需要通过征信获取。
最终,不管是电商还是金融或者其他领域,我们都可以通过数据对用户进行画像,最终建立标签体系,影响我们的业务,最终实现战略目的。
下面我们来具体看一下如何一步步的分析建立整体标签体系。
标签的维度与类型
在我们建立用户标签时,首先要明确基于哪种维度去建立标签。
一般除了基于用户维度(userid)建立用户标签体系外,还有基于设备维度(cookieid)建立相应的标签体系,当用户没有登录设备时,就需要这个维度。当然这两个维度还可以进行关联。
而两者的关联就是需要ID-Mapping算法来解决,这也是一个非常复杂的算法。更多的时候我们还是以用户的唯一标识来建立用户画像。
而标签也分为很多种类型,这里参照常见的分类方式,
从对用户打标签的方式来看,一般分为三种类型:1、基于统计类的标签;2、基于规则类的标签、3、基于挖掘类的标签。下面我们介绍这三种类型标签的区别:
- 统计类标签:这类标签是最为基础也最为常见的标签类型,例如对于某个用户来说,他的性别、年龄、城市、星座、近7日活跃时长、近7日活跃天数、近7日活跃次数等字段可以从用户注册数据、用户访问、消费类数据中统计得出。该类标签构成了用户画像的基础;
- 规则类标签:该类标签基于用户行为及确定的规则产生。例如对平台上“消费活跃”用户这一口径的定义为近30天交易次数>=2。在实际开发画像的过程中,由于运营人员对业务更为熟悉、而数据人员对数据的结构、分布、特征更为熟悉,因此规则类标签的规则确定由运营人员和数据人员共同协商确定;
- 机器学习挖掘类标签:该类标签通过数据挖掘产生,应用在对用户的某些属性或某些行为进行预测判断。例如根据一个用户的行为习惯判断该用户是男性还是女性,根据一个用户的消费习惯判断其对某商品的偏好程度。该类标签需要通过算法挖掘产生。
标签的类型是对标签的一个区分,方便我们了解标签是在数据处理的哪个阶段产生的,也更方便我们管理。
标签分级分类
标签需要进行分级分类的管理,一方面使得标签更加的清晰有条件,另一方面也方便我们对标签进行存储查询,也就是管理标签。

用户画像体系和标签分类从两个不同角度来梳理标签,用户画像体系偏战略和应用,标签分类偏管理和技术实现侧。
把标签分成不同的层级和类别,一是方便管理数千个标签,让散乱的标签体系化;二是维度并不孤立,标签之间互有关联;三可以为标签建模提供标签子集。
梳理某类别的子分类时,尽可能的遵循MECE原则(相互独立、完全穷尽),尤其是一些有关用户分类的,要能覆盖所有用户,但又不交叉。比如:用户活跃度的划分为核心用户、活跃用户、新用户、老用户、流失用户,用户消费能力分为超强、强、中、弱,这样按照给定的规则每个用户都有分到不同的组里。
标签命名
标签的命名也是为了我们可以对标签进行统一的管理,也更好识别出是什么标签。
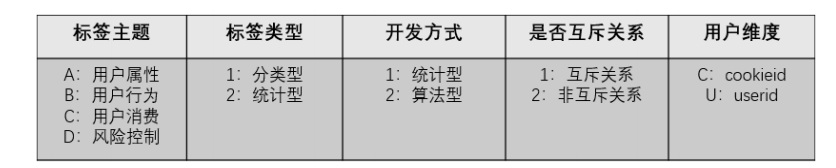
这是一种非常好的命名方式,解释如下:
标签主题:用于刻画属于那种类型的标签,如用户属性、用户行为、用户消费、风险控制等多种类型,可用A、B、C、D等 字母表示各标签主题; 标签类型:标签类型可划为分类型和统计型这两种类型,其中分类型用于刻画用户属于哪种类型,如是男是女、是否是会员、 是否已流失等标签,统计型标签用于刻画统计用户的某些行为次数,如历史购买金额、优惠券使用次数、近30日登陆次数等 标签,这类标签都需要对应一个用户相应行为的权重次数; 开发方式:开发方式可分为统计型开发和算法型开发两大开发方式。其中统计型开发可直接从数据仓库中各主题表建模加工 而成,算法型开发需要对数据做机器学习的算法处理得到相应的标签; 是否互斥标签:对应同一级类目下(如一级标签、二级标签),各标签之间的关系是否为互斥,可将标签划分为互斥关系和 非互斥关系。例如对于男、女标签就是互斥关系,同一个用户不是被打上男性标签就是女性标签,对于高活跃、中活跃、低 活跃标签也是互斥关系; 用户维度:用于刻画该标签是打在用户唯一标识(userid)上,还是打在用户使用的设备(cookieid)上。可用U、C等字 母分别标识userid和cookieid维度。
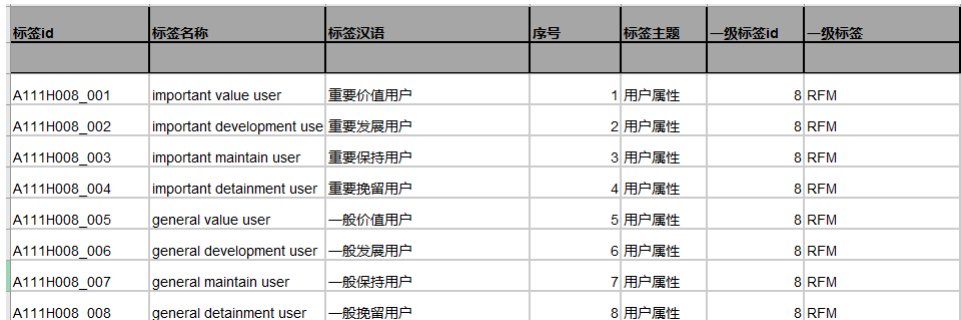
最终形成得标签示例:
对于用户是男是女这个标签,标签主题是用户属性,标签类型属于分类型,开发方式为统计型,为互斥关系,用户 维度为userid。这样给男性用户打上标签“A111U001_001”,女性用户打上标签“A111U001002”,其中 “A111U”为上面介绍的命名方式,“001”为一级标签的id,后面对于用户属性维度的其他一级标签可用“002”、 “003”等方式追加命名,“”后面的“001”和“002”为该一级标签下的标签明细,如果是划分高、中、低活跃 用户的,对应一级标签下的明细可划分为“001”、“002”、“003”。
标签存储与管理
Hive与Druid数仓存储标签计算结果集
因为数据非常大,所以跑标签出来的结果必须要通过hive和druid数仓引擎来完成。
在数据仓库的建模过程中,主要是事实表和维度表的开发。
事实表依据业务来开发,描述业务的过程,可以理解为我们对原始数据做ETL整理后业务事实。
而维度表就是我们最终形成的用户维度,维度表是实时变化的,逐渐的建立起用户的画像。
比如用户维度标签:
首先我们根据之前讨论的用户指标体系,将用户按照人口,行为,消费等等建立相关中间表,注意表的命名。
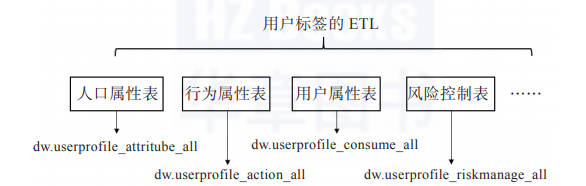
第一张人口属性表:

同样的,其他的也按这种方式进行存储,这种属性类的计算很容易筛选出来。
然后,我们将用户的标签查询出来,汇总到用户身上:
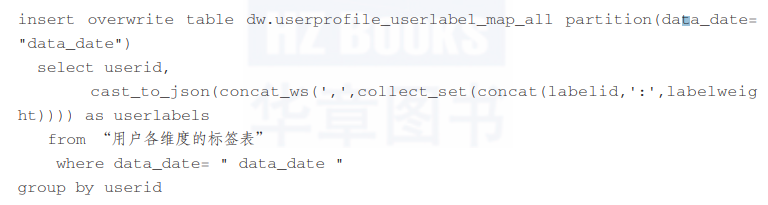
最终用户的标签就形成了
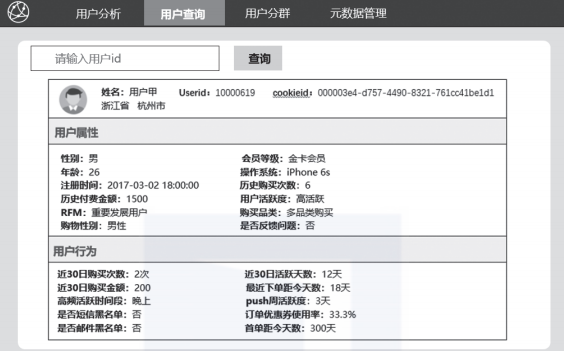
当然,对于复杂的规则和算法类标签,就需要在计算中间表时做更复杂的计算,我们需要在Flink里解决这些复杂的计算,未来开发中我们会详细的讨论,这一部分先根据标签体系把相应的表结构都设计出来。
Mysql存储标签元数据
Mysql对于小数据量的读写速度更快,也更适合我们对标签定义,管理。我们也可以在前端开发标签的管理页面。
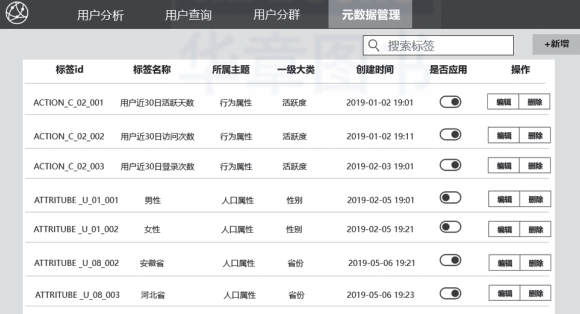
我们在mysql存储的字段如图所示,在页面上提供编辑等功能,在开发标签的过程中,就可以控制标签的使用了。
这样,我们的标签体系已经根据实际的业务情况建立起来了,在明确了标签体系以后,也就明确了我们的业务支撑。