在hbase集群中遇到Call queue is full改了队列大小和长度怎么不管用,本文分析为什么及解决办法
Call queue is full 解决办法
在hbase集群日志中经常会看到Call queue is full on xxx 的问题,我们先找到报这个错误的源头:
org.apache.hadoop.hbase.ipc.ServerRpcConnection#processRequest:
/*
队列长度参数:hbase.ipc.server.max.callqueue.length 默认为10倍hander大小
队列满的大小 = 请求1*请求1大小 + 请求2*请求2大小 + ...+ 请求length*请求length大小
在队列中的大小:callQueueSizeInBytes.sum=队列中的所有请求大小之和
从队列中已经读取出来的大小:totalRequestSize=buf.limit() 也就是ByteBuff中的大小
是否报Call queue is full的条件就是:
1. 在队列中的大小+从队列中已经读取出来的大小> maxQueueSizeInBytes
maxQueueSizeInBytes参数:hbase.ipc.server.max.callqueue.size 默认为1024*1024*1024=1G
*/
// Enforcing the call queue size, this triggers a retry in the client
// This is a bit late to be doing this check - we have already read in the
// total request.
if ((totalRequestSize +
this.rpcServer.callQueueSizeInBytes.sum()) > this.rpcServer.maxQueueSizeInBytes) {
final ServerCall<?> callTooBig = createCall(id, this.service, null, null, null, null,
totalRequestSize, null, 0, this.callCleanup);
this.rpcServer.metrics.exception(RpcServer.CALL_QUEUE_TOO_BIG_EXCEPTION);
callTooBig.setResponse(null, null, RpcServer.CALL_QUEUE_TOO_BIG_EXCEPTION,
"Call queue is full on " + this.rpcServer.server.getServerName() +
", is hbase.ipc.server.max.callqueue.size too small?");
callTooBig.sendResponseIfReady();
return;
}
// 或
//2. 这种情况在相应的rpcScheduler dispatch的时候会判断对应RpcExecutor队列大小是否超过maxQueueLength,如果超过了会直接返回false
if (!this.rpcServer.scheduler.dispatch(new CallRunner(this.rpcServer, call))) {
this.rpcServer.callQueueSizeInBytes.add(-1 * call.getSize());
this.rpcServer.metrics.exception(RpcServer.CALL_QUEUE_TOO_BIG_EXCEPTION);
call.setResponse(null, null, RpcServer.CALL_QUEUE_TOO_BIG_EXCEPTION,
"Call queue is full on " + this.rpcServer.server.getServerName() +
", too many items queued ?");
call.sendResponseIfReady();
}
从代码中我们知道Call queue is full会有两种情况:CALL_QUEUE_TOO_BIG_EXCEPTION
-
一种 hbase.ipc.server.max.callqueue.size too small?
-
一种 too many items queued?
首先尝试办法:
-
当报hbase.ipc.server.max.callqueue.size too small的时候,可以尝试增大
hbase.ipc.server.max.callqueue.size默认是102410241024=1073741824=1G -
当报 too many items queued的时候,可以尝试增大
hbase.ipc.server.max.callqueue.length默认=handlerCount*10
如果这样还不能缓解,当前处理能力有限,handlerCount要增加:
-
HMaster和RegionServer默认都是使用SimpleRpcScheduler,其它Scheduler调整方法类似
-
SimpleRpcScheduler支持4种CallQueue
- Default Queue:
hbase.regionserver.handler.count 默认30 - Priority Queue:
hbase.regionserver.metahandler.count 默认20 - Replication Queue:
hbase.regionserver.replication.handler.count 默认3 - Meta Transition Queue:
hbase.regionserver.replication.handler.count 默认1
- Default Queue:
-
一般调整Default Queue和Priority Queue的handlerCount就可以了,其它两个用的比较少
配置参考
hbase.ipc.server.max.callqueue.size=默认1G 改为3G
hbase.regionserver.handler.count=默认30 改为200
hbase.regionserver.metahandler.count=默认20 改为80
Call queue is full 问题分析
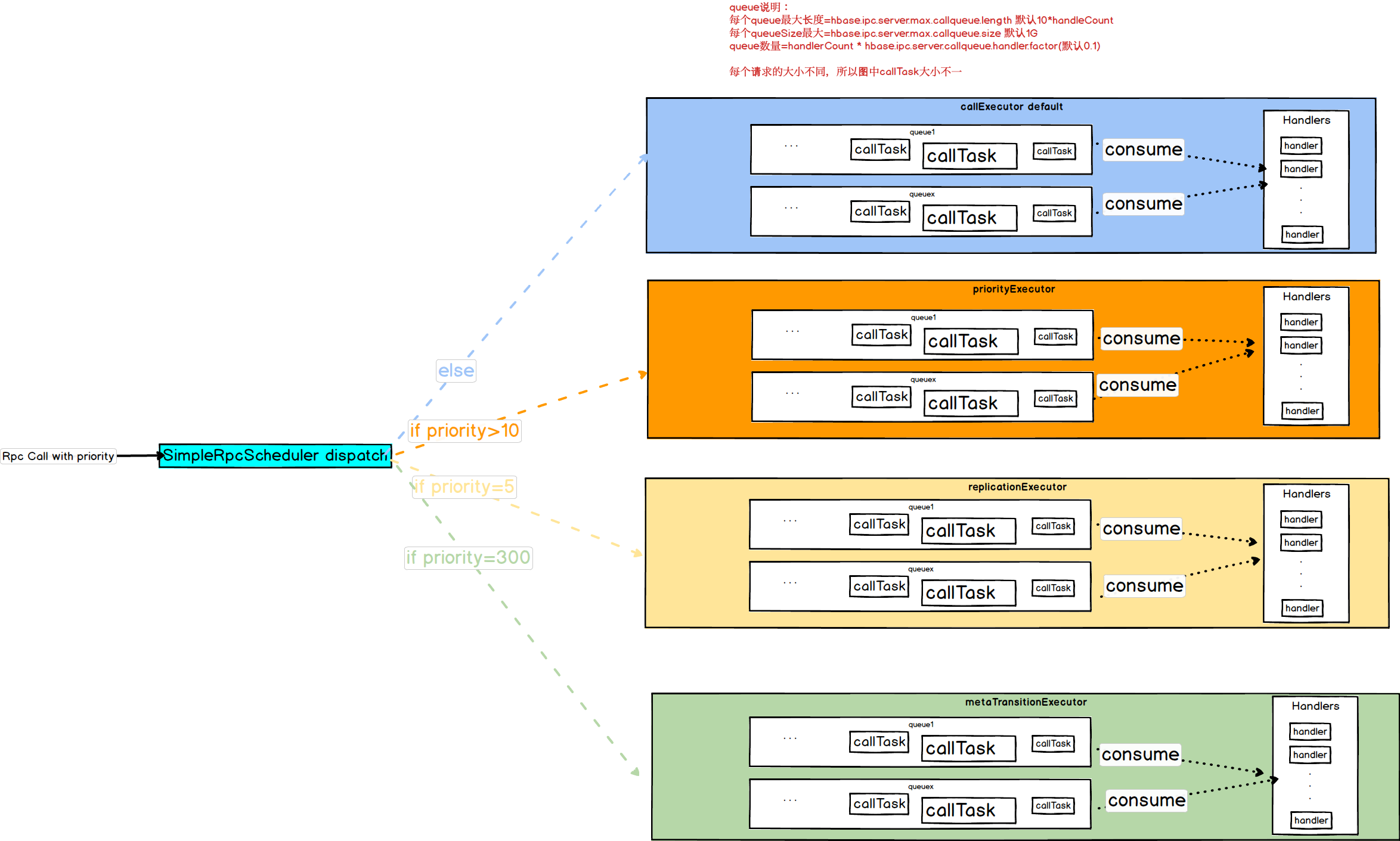
当有rpc请求时server端会调用相应的RpcScheduler,封装成CallRunner,然后dispatch给相应的RpcExecutor去处理,而RpcExecutor不是直接处理,需要通过balancer先把请求放到它的某个队列
-
每个请求数据不同它的大小自然不同,也就是上图callTask
-
queue数量=handlerCount * hbase.ipc.server.callqueue.handler.factor(默认0.1)
-
每个queue最大长度=hbase.ipc.server.max.callqueue.length 默认10*handleCount,可以理解容纳callTask的数量
-
每个queueSize最大=hbase.ipc.server.max.callqueue.size 默认1G,可以理解为所有callTask大小之和
所以:
-
队列容纳能力是由队列数量、队列长度、队列大小综合决定的
-
队列消费能力是由handlerCount决定的
-
队列满的速度是由请求的到来(请求的数量及大小)和请求的消费(handler处理请求)共同决定的
举例
假如现在有一个请求X大小为3M,需要添加到priorityExecutor的队列中
# 假设当前priorityExecutor相关配置
hbase.regionserver.metahandler.count=20 //也就是有20个线程在处理请求
hbase.ipc.server.max.callqueue.length=10*20=200 //每个队列能空纳200个请求
hbase.ipc.server.max.callqueue.size=1g //也就是每个队列中请求大小之和最大为1G
numCallQueues=20*0.1=2 //队列数-
此时如果两个队列中剩余的可容纳请求大小不足3M,无论是否达到maxQueueLength,都会报
Call queue is full on xxx , is hbase.ipc.server.max.callqueue.size too small? -
此时如果两个队列中剩余的可容纳请求大小不足1个,无论是否达到maxQueueSize,都会报
Call queue is full on xxx , too many items queued ?- -
如果报
hbase.ipc.server.max.callqueue.size too small?是检查到队列剩余大小不够了,所以我们可以调大hbase.ipc.server.max.callqueue.size -
如果报
Call queue is full on xxx , too many items queued ?是检查到队列长度不够了,所以我们可以调大hbase.ipc.server.max.callqueue.length
但是请求肯定不能这么理想,来一个处理一个:
-
如果我们调大这两个参数以后,发现还是报,要么调的不够大,要么就是请求来的速度>handler的处理速度了,所以需要加大处理能力,调大handlerCount(这里举例hbase.regionserver.metahandler.count)
-
又由于队列数量默认=handlerCount * hbase.ipc.server.callqueue.handler.factor,所以handlerCount增加不止处理能力增加了,队列容纳能力也会增加
这里以Priority Queue举例,default Queue也是一样,报错不会告诉我们是哪种callqueue,需要我们看日志改参数观察

